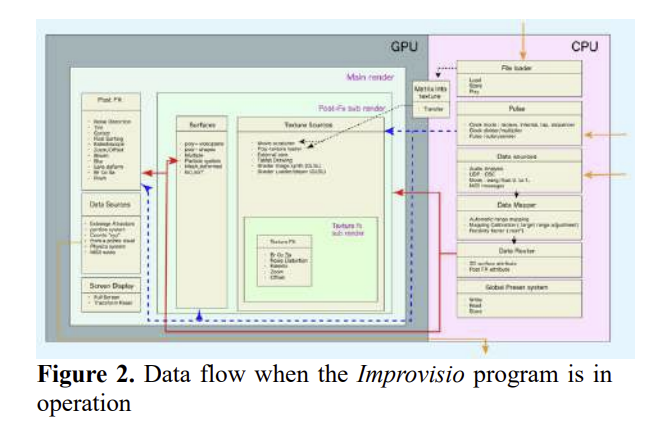
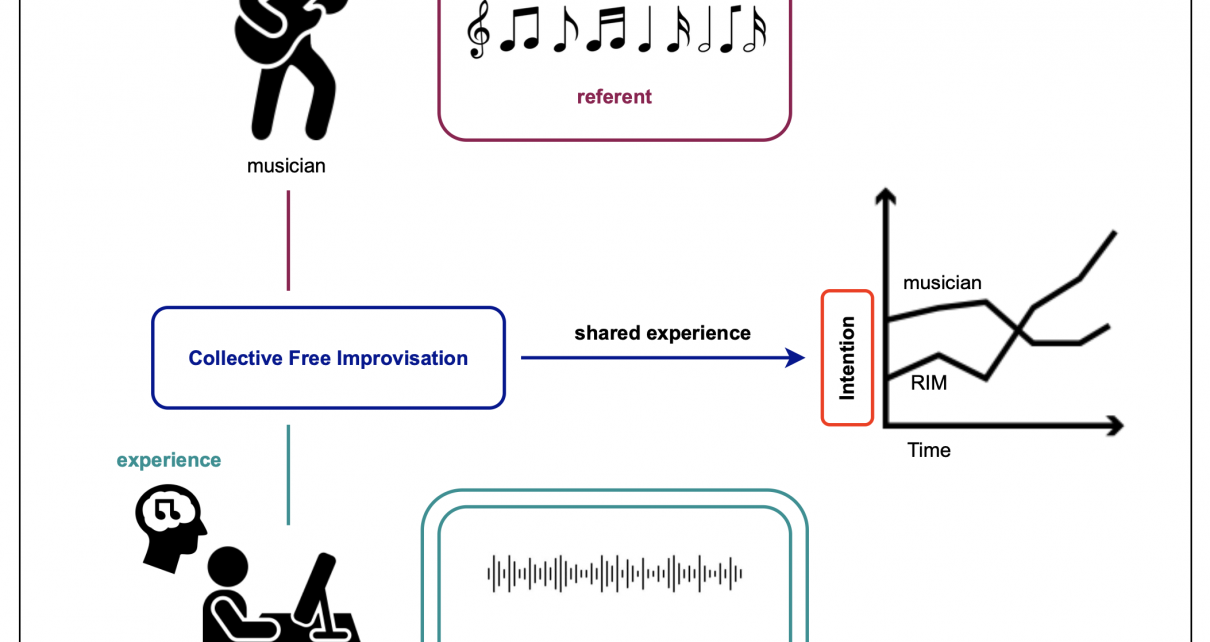
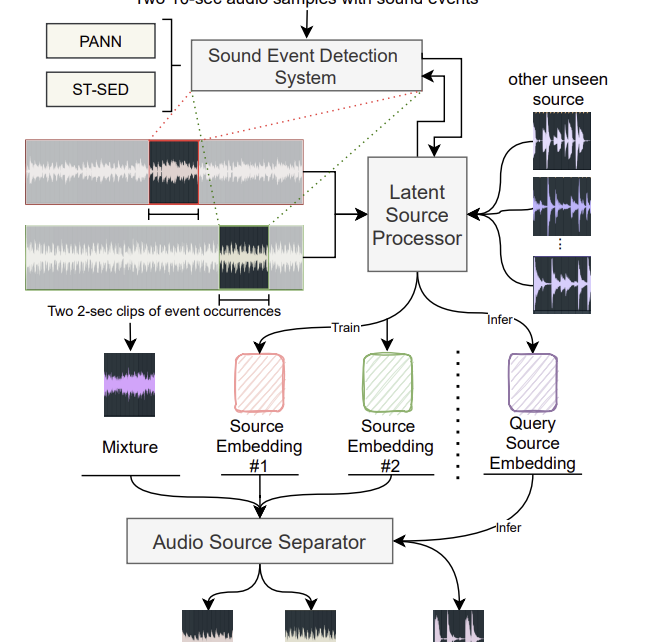
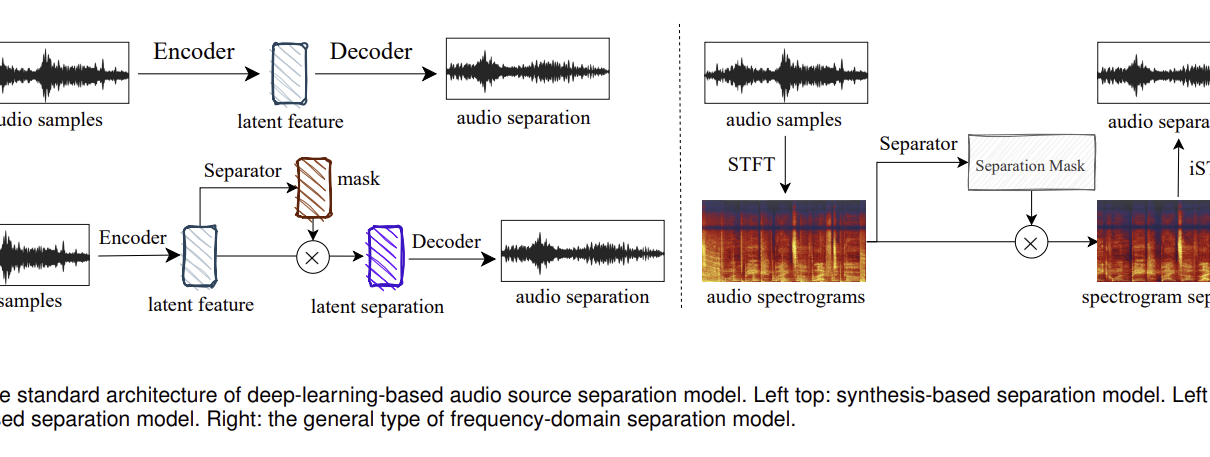
On Monday 25 November, at 19:00 (GMT +1) Marco Fiorini will lead an Online Max Meetup for Notam, the Norwegian centre for technology, art and music. The session will present Somax2 and discuss Music Improvisation and Composition with Co-Creative Agents, showcasing concrete research and artistic outcomes of the REACH project to the online Max community. […]