Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24)
Special Track on AI, the Arts and Creativity.
Published by Nikita Srivatsan, Ke Chen, Shlomo Dubnov and Taylor Berg-Kirkpatrick.
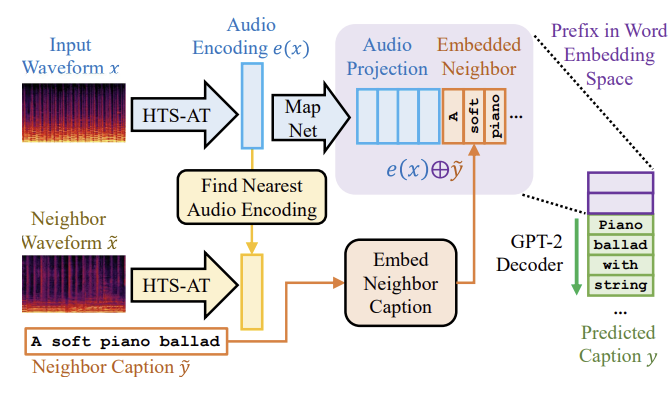
Abstract: In this paper we put forward a new approach to music captioning, the task of automatically generating natural language descriptions for songs. These descriptions are useful both for categorization and analysis, and also from an accessibility standpoint as they form an important component of closed captions for video content. Our method supplements an audio encoding with a retriever, allowing the decoder to condition on multimodal signal both from the audio of the song itself as well as a candidate caption identifed by a nearest neighbor system. This lets us retain the advantages of a retrieval based approach while also allowing for the fexibility of a generative one. We evaluate this system on a dataset of 200k music-caption pairs scraped from Audiostock, a royalty-free music platform, and on MusicCaps, a dataset of 5.5k pairs. We demonstrate signifcant improvements over prior systems across both automatic metrics and human evaluation.