Published by Tornike Karchkhadze, Mohammad Rasool Izadi, Ke Chen, Gerard Assayag, Shlomo Dubnov.
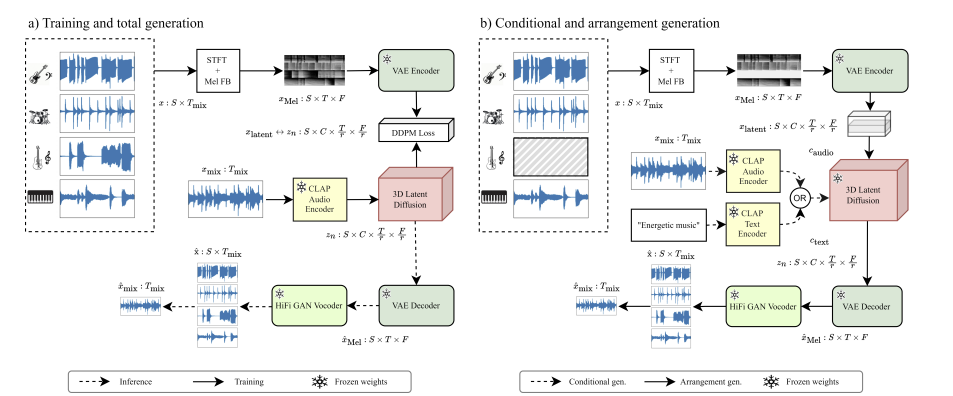
Abstract: Diffusion models have shown promising results in cross-modal generation tasks involving audio and music, such as text-to-sound and text-to-music generation. These text-controlled music generation models typically focus on generating music by capturing global musical attributes like genre and mood. However, music composition is a complex, multilayered task that often involves musical arrangement as an integral part of the process. This process involves composing each instrument to align with existing ones in terms of beat, dynamics, harmony, and melody, requiring greater precision and control over tracks than text prompts usually provide. In this work, we address these challenges by extending the MusicLDM, a latent diffusion model for music, into a multi-track generative model. By learning the joint probability of tracks sharing a context, our model is capable of generating music across several tracks that correspond well to each other, either conditionally or unconditionally. Additionally, our model is capable of arrangement generation, where the model can generate any subset of tracks given the others (e.g., generating a piano track complementing given bass and drum tracks). We compared our model with an existing multi-track generative model and demonstrated that our model achieves considerable improvements across objective metrics for both total and arrangement generation tasks.