Ke Chen, Xingjian Du, Bilei Zhu, Zejun Ma, Taylor Berg-Kirkpatrick, Shlomo Dubnov
ICASSP 2022 – 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2022, Singapore, France. pp.646-650
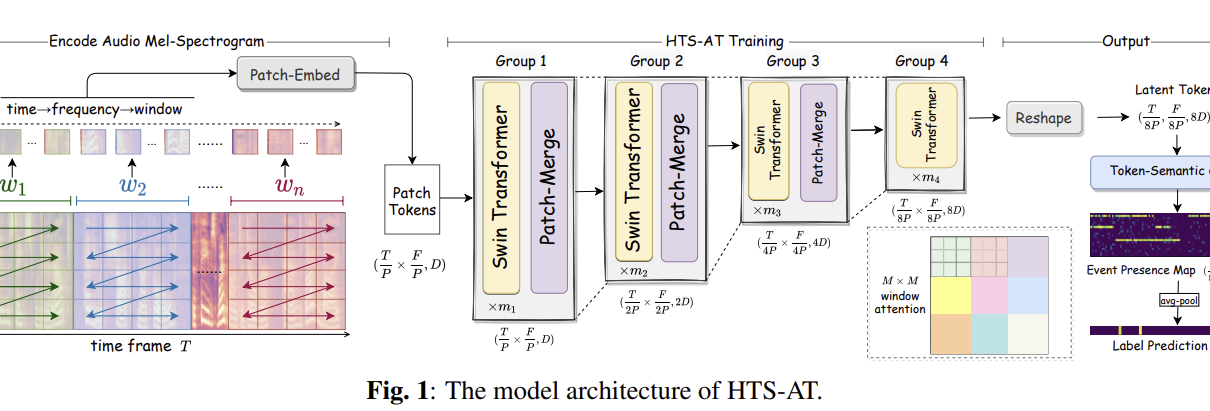
Abstract: Audio classification is an important task of mapping audio samples into their corresponding labels. Recently, the transformer model with self-attention mechanisms has been adopted in this field. However, existing audio transformers require large GPU memories and long training time, meanwhile relying on pretrained vision models to achieve high performance, which limits the model’s scalability in audio tasks. To combat these problems, we introduce HTS-AT: an audio transformer with a hierarchical structure to reduce the model size and training time. It is further combined with a token-semantic module to map final outputs into class featuremaps, thus enabling the model for the audio event detection (i.e. localization in time). We evaluate HTS-AT on three datasets of audio classification where it achieves new state-of-the-art (SOTA) results on AudioSet and ESC-50, and equals the SOTA on Speech Command V2. It also achieves better performance in event localization than the previous CNN-based models. Moreover, HTS-AT requires only 35% model parameters and 15% training time of the previous audio transformer. These results demonstrate the high performance and high efficiency of HTS-AT.