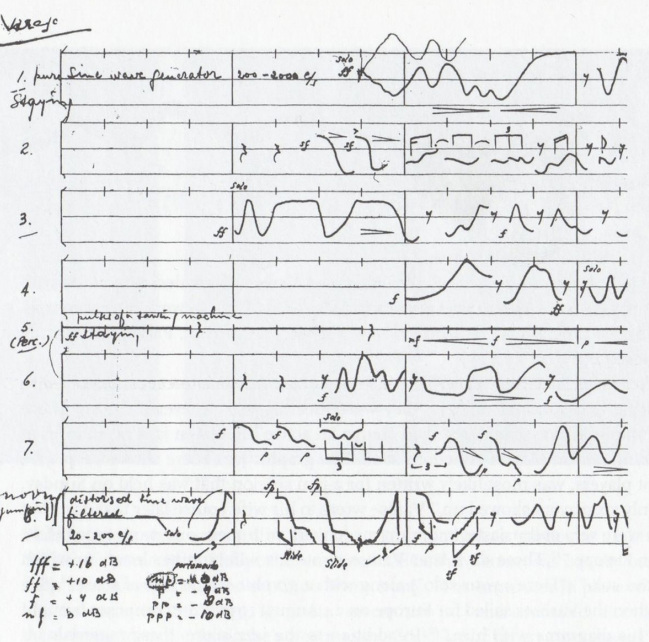
Born from the collaboration between the Jazz and Electronic Music departments of the Alfredo Casella Conservatory of L’Aquila (Italy), the Sound Thinkin’ project – a music improvisation workshop with co-creative computer agents – will begin on February 28, 2024.The workshop will end in an evening of concerts that will be part of the annual review […]