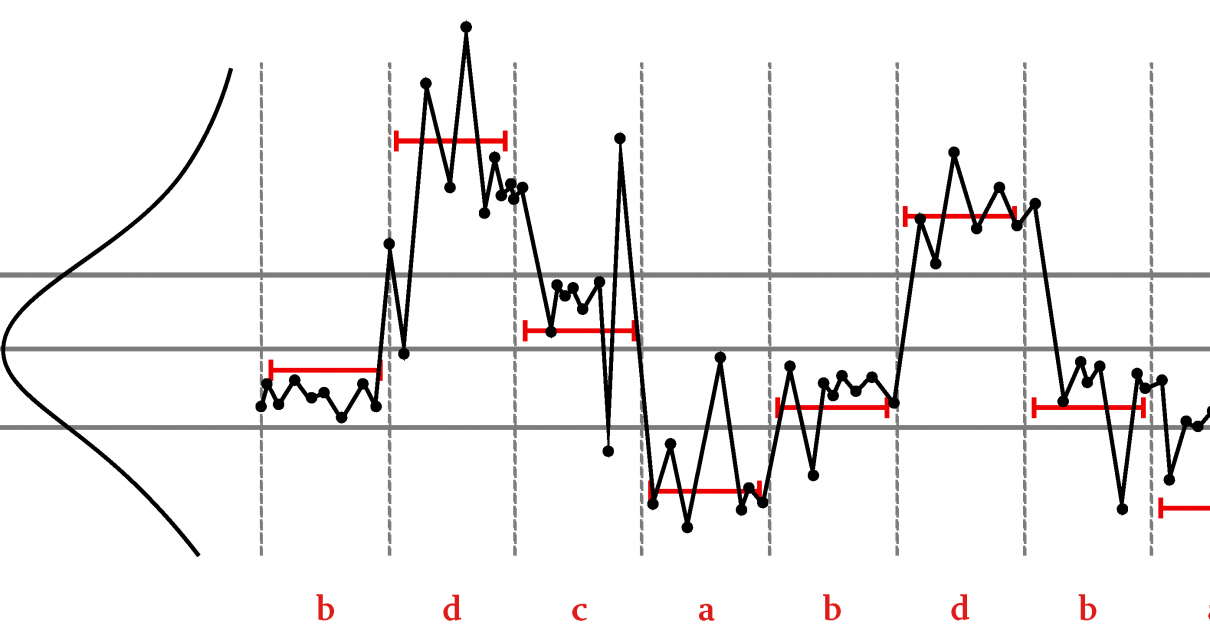
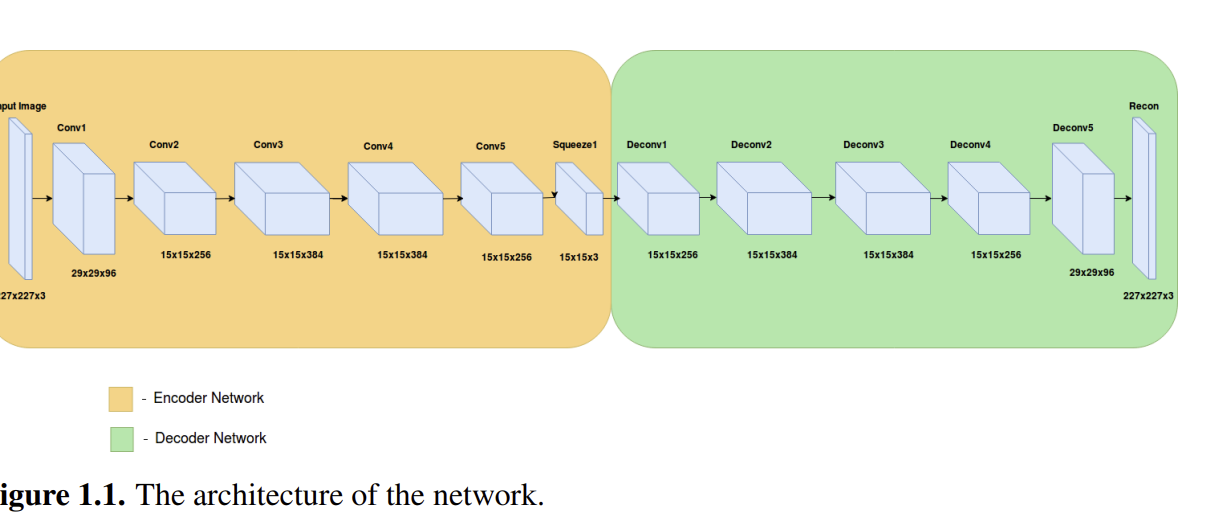
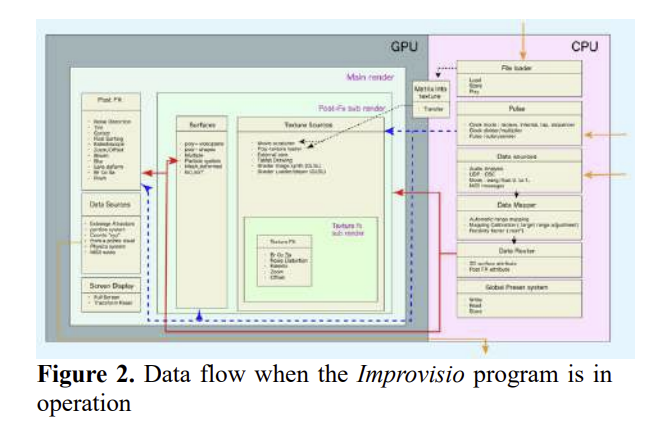
Article by Alberto Gatti and Marco Fiorini (equal contribution) has been accepted for the Sound and Music Computing Conference (SMC2025) in Graz, Austria. Read the full paper Video demo Abstract: This paper presents a novel methodology for creating dynamic auditory landscapes in co-creative musical interaction through the Somax2 system, introducing a new approach to spatial […]