Published by Ke Chen, Jiaqi Su, Taylor Berg-Kirkpatrick, Shlomo Dubnov, Zeyu Jin.
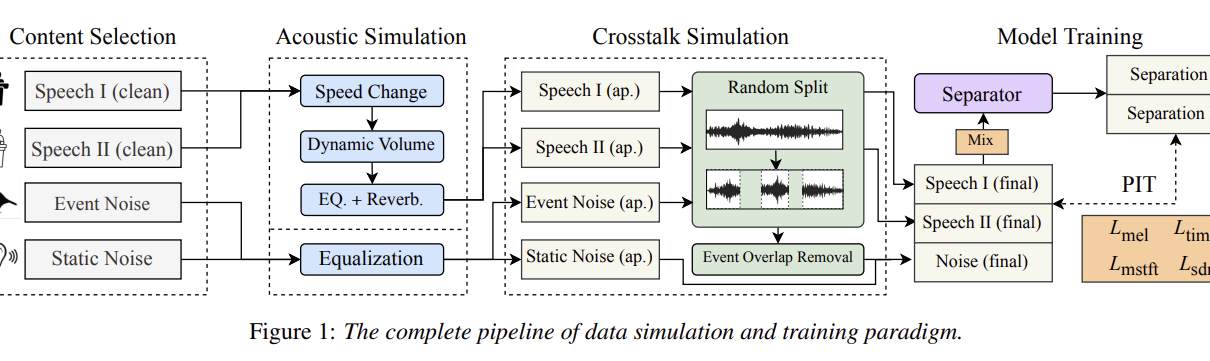
Abstract: Achieving robust speech separation for overlapping speakers in various acoustic environments with noise and reverberation remains an open challenge. Although existing datasets are available to train separators for specific scenarios, they do not effectively generalize across diverse real-world scenarios. In this paper, we present a novel data simulation pipeline that produces diverse training data from a range of acoustic environments and content, and propose new training paradigms to improve quality of a general speech separation model. Specifically, we first introduce AC-SIM, a data simulation pipeline that incorporates broad variations in both content and acoustics. Then we integrate multiple training objectives into the permutation invariant training (PIT) to enhance separation quality and generalization of the trained model. Finally, we conduct comprehensive objective and human listening experiments across separation architectures and benchmarks to validate our methods, demonstrating substantial improvement of generalization on both non-homologous and real-world test sets.